Estimating the Power Spectral Density of Ambient Seismic Noise

Contents
1 Introduction
Benefiting by the installation of seismic stations, we can, to some extend, understand that how our planet Earth sings. These sounds released by our planet generate the vibration signals that can be recorded by the seismic receivers. Seismic ambient noise, which is generated by ocean infragravity waves, commonly referred to as “Hum” ($30 - 500 \ s $), microseisms ( the primary and secondary, $1 - 30 \ s$) and human noise (cultural noise, $0.1 - 1 \ s$) (Nakata et al., 2019). How to estimate the level of seismic ambient noise? The power spectral density (PSD) is usually used to describe the seismic noise spectra. Here, we briefly introduce the steps of estimating the seismic noise, some Python codes included. By the way, the PSD model of the seismic ambient noise has been introduced by Peterson (1993).
2 Basic principles
Supposing that we have a stochastic time series (randomly generated noise) $u(t)$, and the discrete form is represented as $u(n)$. The assumption that $u(t)$ is periodic is given here, we can directly estimate the its PSD as $$ p(\omega) = \frac{1}{T}|U(\omega)|^2 \tag{1}, $$ where $U(\omega)$ is the Fourier spectrum of $u(t)$, namely $U(\omega)=\int_{-T/2}^{T/2}u(t)e^{-i\omega t}dt$.
The discrete form of $p(\omega)$ is given by $$ p(k)=\frac{1}{N}|U(k)|^2 \tag{2}, $$ where, $N$ is the total data point number of $u(n)$.
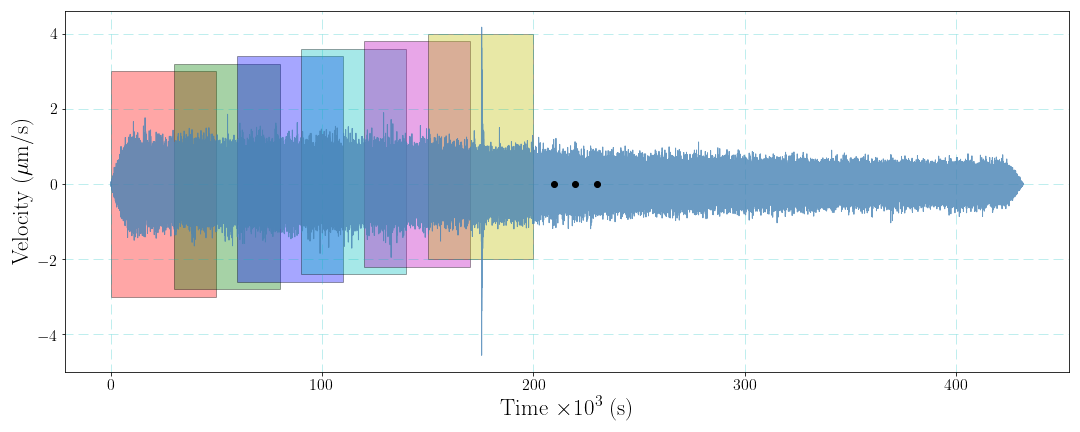
However, the seismic noise is not stochastic stable and the direct estimation method is thus not proper. One may think that we can divide the noise time series into several segments to repeat the estimations of the PSD and calculate the average PSD to obtain the final result. Indeed, this data processing will improve the stability of the PSD of the seismic noise. Here we cut the data into $M$ segments and the length of every segment is $L$, the average PSD is obtained by $$ \bar{p}(k)=\frac{1}{M}\sum_{m=1}^M[\frac{1}{L}|U_m(k)|^2] \tag{3}. $$ Similar to the idea of short time Fourier transform, window function can be also taken into consideration. Dividing data into several segments is the situation of rectangle window function. Sometimes we may use non-rectangle window function to conduct the data processing.
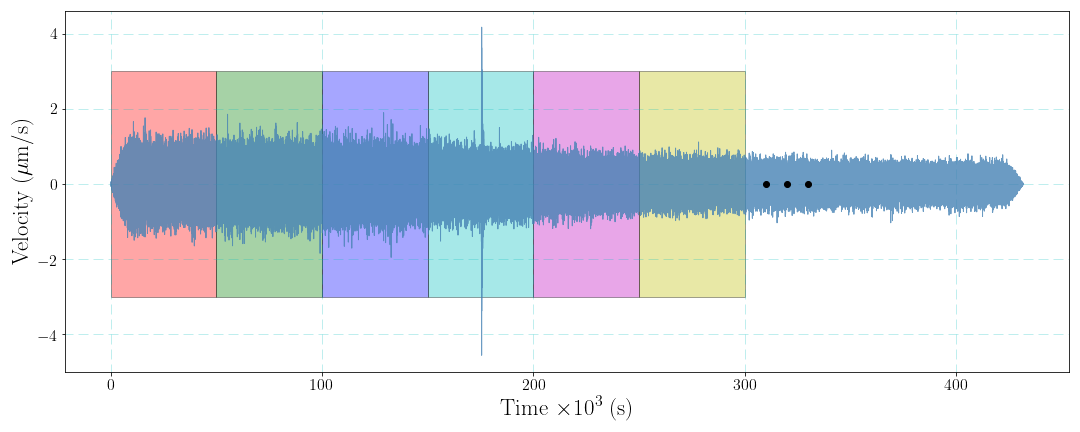
Finally, considering the data overlap can improve stability of the PSD result. The choice of the length of overlap, however, may need to tested for the perfect situation.
3 A Realistic Example
Here we retrieve $LHZ$ component seismic noise data recoded by station $MSEY$ of network $II$ from $2018-07-29T00:00:00$ to $2018-08-02T00:00:00$ in Seychelles, a island in the Indian Ocean.
The sampling rate is $1 \ Hz$, so the maximum frequency is $0.5 \ Hz$ according to the $ Nyquist $ sampling theorem.
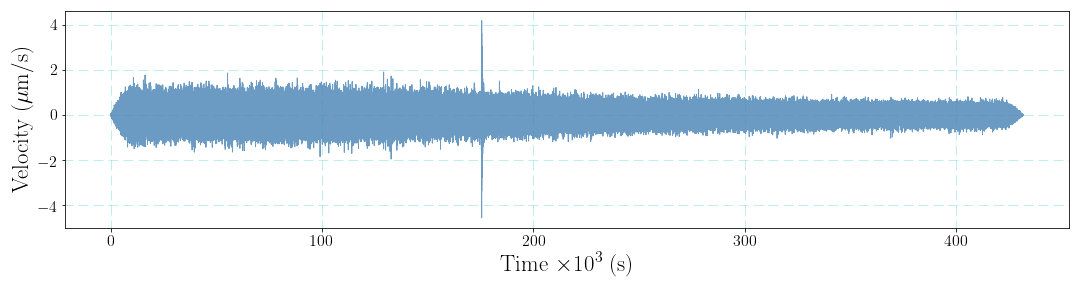
We will compare the PSD results from different estimation strategies in the following parts. Some pre-processing steps should be finished, e.g., removing mean, trend, doing tapering and removing the instrument response. The velocity waveform after removing instrument response is show as the below figure.
|
|
We implement a Python method to estimate the average PSD of discrete time series with dividing the data into several segments:
|
|
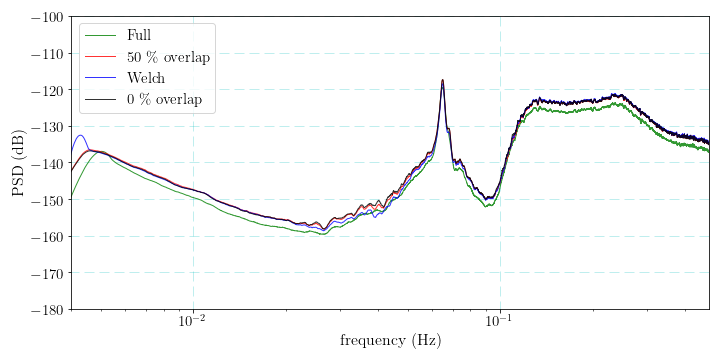
The PSD results from several estimation strategies are computed.
|
|
4 The PSD Probability Density Function Estimation
The PSD probability density function (PSDPDF) is used to visualize the PSD of seismic noise and one can consider long-duration seismic noise data. By dividing the noise time series into many segments (overlap involved if necessary), we map every PSD curve into the PSDPDF figure. In detail, we accumulate the number of all PSD curve at every frequency value, and the probability at some power value and frequency could be obtained by dividing the cumulative number is with the sum of all numbers at this frequency.
Here we collect one-year seismic noise data recorded by a seismic station ($CASY$ in network $IU$) in Antarctica in 2020. We divide the noise time series into daily segments to compute the PSDPDF of noise at this seismic station.
|
|
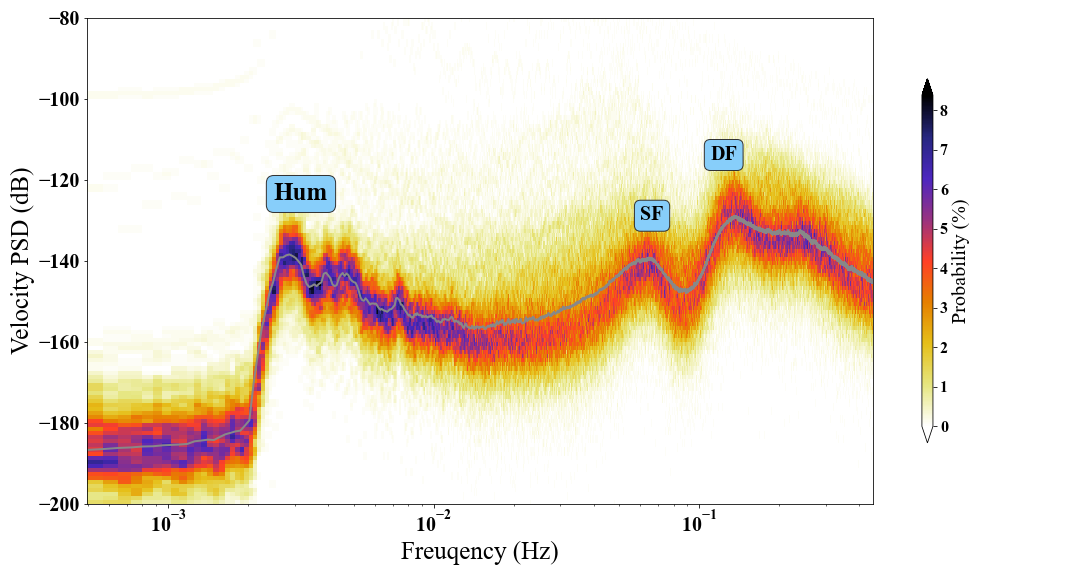
The hum, SF (single-frequency, the primary) and DF (double-frequency, the secondary) microseisms are marked on the figure. The gray curve denotes the average PSD from $366$-day ambient seismic noise data segments.
Bibliography
Nakata, Nori; Gualtieri, Lucia; Fichtner, Andreas (2019). *Seismic Ambient Noise || Noise-Based Monitoring. , 10.1017/9781108264808(9).
Peterson, J. 1993. Observations and modeling of seismic background noise. U.S. Geol. Surv. Tech. Rept., 93-322, 1–95
Author Geophydog
LastMod 2021-03-11